

Последние записи
- Как в Python+Selenium webdriver открыть новую вкладку в уже открытом браузере?
- Lazarus, проверка существования строки таблице
- BASM и record, обращение к полям записи
- Web PHP Framework Symfony
- Относительный путь для вывода картинки на html странице
- Массовое открытие гиперссылок в браузере
- Скопировать значение строки из таблицы в textarea
- Рамки для страниц отчетов
- Вывод StdOut консоли в TMemo
- Чтение из файла большого размера (нехватка памяти)

Интенсив по Python: Работа с API и фреймворками 24-26 ИЮНЯ 2022. Знаете Python, но хотите расширить свои навыки?
Slurm подготовили для вас особенный продукт! Оставить заявку по ссылке - https://slurm.club/3MeqNEk

Online-курс Java с оплатой после трудоустройства. Каждый выпускник получает предложение о работе
И зарплату на 30% выше ожидаемой, подробнее на сайте академии, ссылка - ttps://clck.ru/fCrQw
21st
Фев
 Компилятор домашнего приготовления. Часть 2
Компилятор домашнего приготовления. Часть 2
Ветер… У вас тоже на улице ветерок? Возможно, он принесет дождь, по крайней мере, разгонит эту изнурительную жару. Но пока этого не случится, людям стоит спрятаться от палящих лучей солнца в помещения с кондиционером и холодильником, в котором охлаждается квасок или живое пиво. Ну, а пока это счастье свежеет от фреонного холода, есть время продолжить разработку своего компилятора…
23rd
Сен
Компилятор домашнего приготовления. Часть 1
Почему мне пришла в голову идея разработать собственный компилятор? Однажды мне на глаза попалась книга, где описывались примеры проектирования в AutoCAD на встроенном в него языке AutoLISP. Я захотел c ними разобраться, но прежде меня заинтересовал сам ЛИСП. “Неплохо бы поближе познакомиться с ним”, – подумал я и начал подыскивать литературу и среду разработки. С литературой все оказалось просто – по ЛИСПу ее море в Интернете. Достаточно зайти на портал [1]. Дело оставалось за малым – найти хорошую среду программирования, и вот тут-то начались трудности. Компиляторов под ЛИСП тоже немало, но все они оказались мне малопонятны. Ни один пример из Вики, по разным причинам, не отработал нормально в скачанных мною компиляторах. Собственно, серьезно я с ними не разбирался, но, увы, во многих не нашел как скомпилировать EXE-файл. Самое интересное, что компиляторы эти были собраны разными людьми практически в домашних условиях…
Виталий Белик
by Stilet
И мне пришла в голову мысль: а почему бы не попробовать самому написать свой компилятор или, основываясь на каком-либо диалекте какого-либо языка, свой собственный язык программирования? К тому же на форумах я часто видел темы, где слезно жаловались на тиранов-преподавателей, поставивших задачу написания курсовой – компилятора или эвалюатора (программы, вычисляющей введенное в виде строки выражение). Мне стало еще интереснее: а что если простому студенту, не искушенному книгами Вирта или Страуструпа, написать такую программу? Появился мотив.
In the Beginning
Итак, начнем. Прежде всего, нужно поставить задачу хотя бы на первом этапе. Задача будет банальная: доказать самому себе, что написание компилятора не такой уж сложный и страшный процесс. И что мы, хитрые и смекалистые, способны родить в муках собственного творчества шедевр, который, возможно, полюбится массам. Да и вообще: приятно писать программы на собственном языке, не так ли?
Что ж, цель поставлена. Теперь самое время определиться со следующими пунктами:
- Под какую платформу будет компилировать код программа?
- На каком языке будет код, переводимый в машинный язык?
- На чем будем писать сам компилятор?
Первый пункт достаточно важен, ибо широкое разнообразие операционных систем (даже три монстра – Windows, Linux и MacOS) уже путают все карты. Их исполняемые файлы по-разному устроены, так что нам, простым смертным, придется выбрать из этой “кагалы” одну операционную систему и, соответственно, ее формат исполняемых файлов. Я предлагаю начать с Windows, просто потому, что мне нравится эта операционная система более других. Это не значит, что я терпеть не могу Linux, просто я его не очень хорошо знаю, а такие начинания лучше делать по максимуму, зная систему, для которой проектируешь.
Два остальных пункта уже не так важны. В конце концов, можно придумать свой собственный диалект языка. Я предлагаю взять один из старейших языков программирования – LISP. Из всех языков, что я знаю, он мне кажется более простым по синтаксису, более атомарным, ибо в нем каждая операция берется в скобочки; таким образом, к нему проще написать анализатор. С выбором, на чем писать, еще проще: писать нужно на том языке, который лучше всего знаешь. Мне ближе паскалевидные языки, я хорошо знаю Delphi, поэтому в своей разработке я избираю именно его, хотя никто не мешает сделать то же самое на Си. Оба языка прекрасно подходят для написания такого рода программ. Я не беру в расчет Ассемблер потому, что его диалект приближен к машинному языку, а не к человеческому.
To Shopping
Выяснив платформу, для которой будем писать компилятор (я имею в виду Win32), подберем все необходимое для комфортной работы. Давайте составим список, что же нам пригодится в наших изысканиях.
Для начала нам просто крайне необходимо выяснить, как же все-таки компиляторы генерируют исполняемые EXE-файлы под Windows. Для этого стоит почитать немного об устройстве этих “экзэшек”, как их часто называют, покопаться в их “кишках”. В этом могут помочь современные отладчики и дизассемблеры, способные показать, из чего состоит “экзэшка”. Я знаю два, на мой взгляд, лучших инструмента: OllyDebugger (он же “Оля”) и The Interactive Disassembler (в простонародье зовущийся IDA).
Оба инструмента можно достать на их официальных сайтах http://www.ollydbg.de/ и http://www.hex-rays.com/idapro. Они помогут нам заглянуть в святая святых – храм, почитаемый загрузчиком исполнимых файлов, – и посмотреть, каков интерьер этого храма, дабы загрузчик наших экзэшек чувствовал себя в нем так же комфортно, как “ковбой в подгузниках Хаггис”.
Также нам понадобится какая-нибудь экзэшка в качестве жертвы, которую мы будем препарировать этими скальпелями-дизассемблерами. Здесь все сложнее. Дело в том, что благородные компиляторы имеют дурную привычку пихать в экзэшник, помимо необходимого для работы кода, всякую всячину, зачастую ненужную. Это, конечно, не мусор, но без него вполне можно обойтись, а вот для нашего исследования внутренностей экзэшек он может стать серьезной помехой. Мы ведь не Ричарды Столлманы и искусством реверсинга в совершенстве не владеем. Поэтому нам лучше было бы найти такую программу, которая содержала бы в себе как можно меньше откомпилированного кода, дабы не отвлекаться на него. В этом нам может помочь компилятор Ассемблера для Windows. Я знаю два неплохих компилятора: Macro Assembler (он же MASM) и Flat Assembler (он же FASM). Я лично предпочитаю второй – у него меньше мороки при компилировании программы, есть собственный редактор, в отличие от MASM компиляция проходит нажатием одной-единственной кнопки. Для MASM разработаны среды проектирования, например MASM Builder. Это достаточно неплохой визуальный инструмент, где на форму можно кидать компоненты по типу Delphi или Visual Studio, но, увы, не лишенный багов. Поэтому воспользуемся FASM. Скачать его можно везде, это свободно распространяемый инструмент. Ну и, конечно, не забудем о среде, на которой и будет написан наш компилятор. Я уже сказал, что это будет Delphi. Если хотите конкретнее – Delphi 6.
The Theory and Researching
Прежде чем приступить к написанию компилятора, неплохо бы узнать, что это за формат “экзэшка” такой. Согласно [2], Windows использует некий PE-формат. Это расширение ранее применявшегося в MS-DOS, так называемого MZ формата [3]. Сам чистый MZ-формат простой и незатейливый – это 32 байта (в минимальном виде, если верить FASM; Турбо Паскаль может побольше запросить), где содержится описание для DOS-загрузчика. В Windows его решили оставить, видимо, для совместимости со старыми программами. Вообще, если честно, размер DOS-заголовка может варьироваться в зависимости от того, что после этих 28 байт напихает компилятор. Это может быть самая разнообразная информация, например для операционок, которые не смогли бы использовать скомпилированный DOS или Windows-экзэшник, представленная в качестве машинного кода, который прерываниями BIOS выводит на экран надпись типа “Эта программа не может быть запущена…”. Кстати, сегодняшние компиляторы поступают так же.
Давайте посмотрим на это чудо техники, воспользовавшись простенькой программой, написанной на чистом Ассемблере FASM (см. Рис. 1):
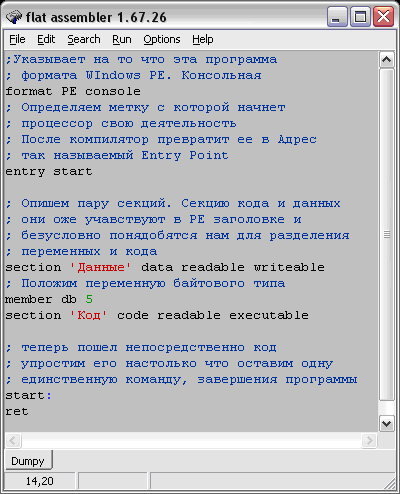
Рис. 1. Исходник для препарирования
Сохраним файл под неким именем, например Dumpy. Нажмем F9 или выберем в меню пункт RUN. В той же папке будет создан EXE-файл. Это и будет наша жертва, которую мы будем препарировать. Теперь ничто не мешает нам посмотреть: “из чего же, из чего же сделаны наши девчонки?”.
Запустим OllyDebuger. Откроем в “Оле” наш экзэшник. Поскольку фактически кода в нем нет, нас будет интересовать его устройство, его структура. В меню View есть пункт Memory, после выбора которого “Оля” любезно покажет структуру загруженного файла (см. Рис. 2):
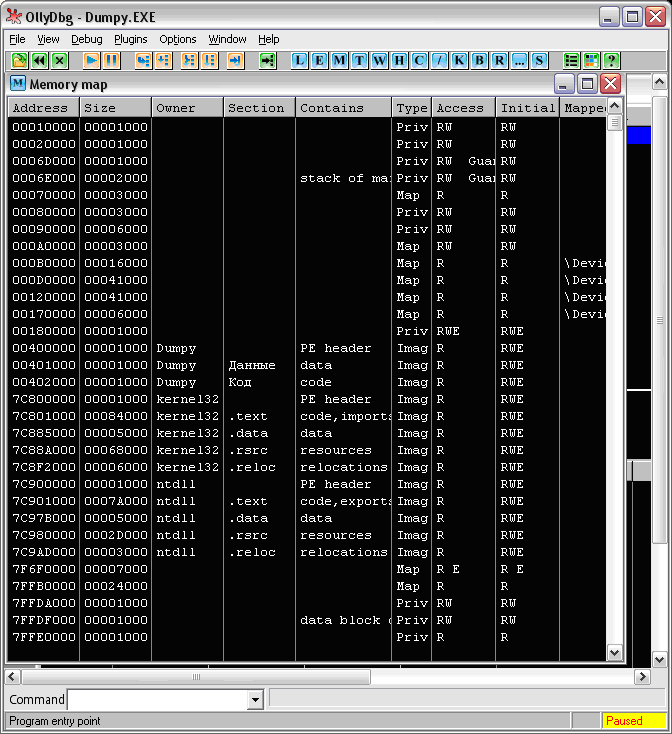
Рис. 2. Карта памяти Dumpy
Это не только сам файл, но и все, что было загружено и применено вместе с ним, библиотеки, ресурсы программы и библиотек, стек и прочее, разбитое на блоки, называемые секциями. Из всего этого нас будут интересовать три секции, владелец которых Dumpy, – это непосредственно содержимое загруженного файла.
Собственно, эти секции были описаны нами в исходнике, я не зря назвал их по-русски (ведь операционной системе все равно, как названы секции, главное – их имена должны укладываться точь-в-точь в 8 байт. Это придется учесть обязательно).
Заглянем в первую секцию PE Header. Сразу же можем увидеть (см. Рис. 3), что умная “Оля” подсказывает нам, какие поля* у этой структуры:
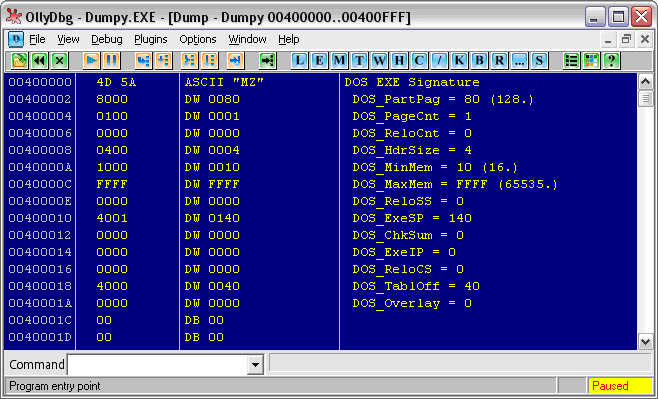
Рис. 3. MZ-заголовок
* Комментарий автора.
Сразу хочу оговориться, не все из этих полей нам важны. Тем паче что сам Windows использует из них от силы 2-3 поля. Прежде всего, это DOS EXE Signature – здесь (читайте в Википедии по ссылке выше) помещаются две буквы MZ – инициалы создателя MS-DOS, и поле DOS_PartPag. В нем указывается размер MZ-заголовка в байтах, после которых помещается уже PE-заголовок.
Сразу хочу оговориться, не все из этих полей нам важны. Тем паче что сам Windows использует из них от силы 2-3 поля. Прежде всего, это DOS EXE Signature – здесь (читайте в Википедии по ссылке выше) помещаются две буквы MZ – инициалы создателя MS-DOS, и поле DOS_PartPag. В нем указывается размер MZ-заголовка в байтах, после которых помещается уже PE-заголовок.
Последнее поле, которое для нас важно, находится по смещению 3Ch от начала файла (см. Рис. 4):
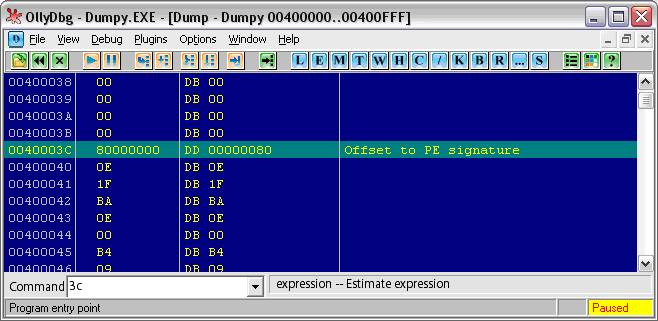
Рис. 4. Смещение на PE-заголовок
Это поле – точка начала РЕ-заголовка. В Windows, в отличие от MS-DOS, MZ-заголовок заканчивается именно на отметке 40**, что соответствует 64 байтам. При написании компилятора будем соблюдать это правило неукоснительно.
* Комментарий автора.
Обратите внимание! Далее, с 40-го смещения, “Оля” показывает какую-то белиберду. Эта белиберда есть атавизм DOS и представляет из себя оговоренную выше информацию, с сообщением о том, что данная программа может быть запущена только под DOS-Windows. Этакий перехватчик ошибок. Как показывает практика, этот мусор можно без сожаления выкинуть. Наш компилятор не будет генерировать его, сразу переходя к PE-заголовку.
Обратите внимание! Далее, с 40-го смещения, “Оля” показывает какую-то белиберду. Эта белиберда есть атавизм DOS и представляет из себя оговоренную выше информацию, с сообщением о том, что данная программа может быть запущена только под DOS-Windows. Этакий перехватчик ошибок. Как показывает практика, этот мусор можно без сожаления выкинуть. Наш компилятор не будет генерировать его, сразу переходя к PE-заголовку.
Что ж, перейдем непосредственно к PE-заголовку (см. Рис. 5). Как показывает “Оля”, нам нужно перейти на 80-й байт. Да, чуть не забыл. Все числа адресации указываются в 16-тиричной системе счисления. Для этого после чисел ставится латинская буква “H”. “Оля” не показывает ее, принимая эту систему по умолчанию для адресации. Это нужно учесть, чтобы не запутаться в исследованиях. Фактически 80h – это 128-й байт.
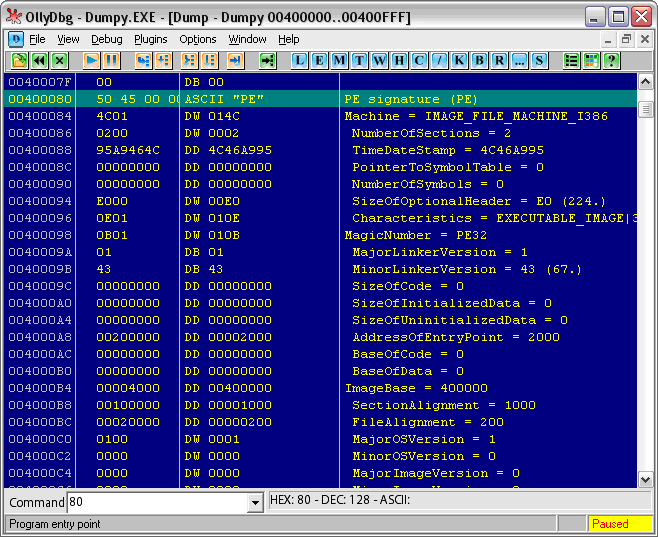
Рис. 5. Начало РЕ-заголовка
Вот она, святая обитель характеристик экзэшника. Именно этой информацией пользуется загрузчик Windows, чтобы расположить файл в памяти и выделить ему необходимую память для нужд. Вообще, считается, что этот формат хорошо описан в литературе. Достаточно выйти через Википедию по ссылкам в ее статьях [4] или банально забить в поисковик фразу вроде “ФОРМАТ ИСПОЛНЯЕМЫХ ФАЙЛОВ PortableExecutables (PE)”, как сразу же можно найти кучу описаний. Поэтому я поясню только основные его поля, которые нам понадобятся непосредственно для написания компилятора…
Прежде всего, это PE Signature – 4-хбайтовое поле. В разной литературе оно воспринимается по-разному. Иногда к нему приплюсовывают еще поле Machine, оговариваясь, чтобы выравнять до 8 байт. Мы же, как любители исследовать, доверимся “Оле” с “Идой” и будем разбирать поля непосредственно по их подсказкам. Это поле содержит две латинские буквы верхнего регистра “PE”, как бы намекая нам, что это Portable Executable-формат.
Следующее за ним поле указывает, для какого семейства процессоров пригоден данный код. Всего их, как показывает литература, 7 видов:
0000h __unknown
014Ch __80386
014Dh __80486
014Eh __80586
0162h __MIPS Mark I (R2000, R3000)
0163h __MIPS Mark II (R6000)
0166h __MIPS Mark III (R4000)
014Ch __80386
014Dh __80486
014Eh __80586
0162h __MIPS Mark I (R2000, R3000)
0163h __MIPS Mark II (R6000)
0166h __MIPS Mark III (R4000)
Думаю, нам стоит выбрать из всего этого второй вид – 80386. Кстати, наблюдательные личности могли заметить, что в компиляторах Ассемблера есть директива, указывающая, какое семейство процессора использовать, как, например, в MASM (см. Рис. 6):
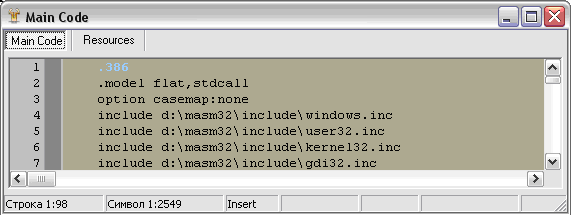
Рис. 6. Указание семейства процессоров в МАСМ
386 как раз и говорит о том, что в этом поле будет стоять значение 014Ch***.
* Комментарий автора.
Обратите внимание на одну небольшую, но очень важную особенность: байты в файле непосредственно идут как бы в перевернутом виде. Вместо 14С в файл нужно писать байты в обратном порядке, начиная с младшего, т. е. получится 4С01 (0 здесь дополняет до байта. Это для человеческого глаза сделано, иначе все 16-тиричные редакторы показывали бы нестройные 4С1. (Согласитесь, трудно было понять, какие две цифры из этого числа к какому байту относятся.) Эту особенность обязательно придется учесть. Для простоты нелишним было бы написать пару функций, которые число превращают в такую вот перевернутую последовательность байт (что мы в дальнейшем и сделаем).
Обратите внимание на одну небольшую, но очень важную особенность: байты в файле непосредственно идут как бы в перевернутом виде. Вместо 14С в файл нужно писать байты в обратном порядке, начиная с младшего, т. е. получится 4С01 (0 здесь дополняет до байта. Это для человеческого глаза сделано, иначе все 16-тиричные редакторы показывали бы нестройные 4С1. (Согласитесь, трудно было понять, какие две цифры из этого числа к какому байту относятся.) Эту особенность обязательно придется учесть. Для простоты нелишним было бы написать пару функций, которые число превращают в такую вот перевернутую последовательность байт (что мы в дальнейшем и сделаем).
Следующее важное для нас поле – NumberOfSections. Это количество секций без учета PE-секции. Имеются в виду только те секции, которые принадлежат файлу (в карте памяти их владелец – Dumpy). В нашем случае это “Данные” и “код”.
Следующее поле хоть и не столь важно, но я его опишу. Это TimeDateStamp – поле, где хранится дата и время компиляции. Вообще, я его проигнорирую, не суть важно сейчас, когда был скомпилирован файл. Впрочем, если кому захочется помещать туда время, то флаг в руки.
Сразу хочу предупредить, что меня как исследователя не интересовали поля с нулевыми значениями. На данном этапе они действительно неважны, поэтому в компиляторе их и нужно будет занулить.
Следующее важное поле – SizeOfOptionalHeader. Оно содержит число, указывающее, сколько байт осталось до начала описания секций. В принципе, нас будет устраивать число 0Eh (224 байта).
Далее идет поле “характеристики экзэшника”. Мы и его будем считать константным:
Characteristics (EXECUTABLE_IMAGE|32BIT_MACHINE|LINE_NUMS_STRIPPED|LOCAL_SYMS_STRIPPED)
И равно оно 010Eh. На этом поле заканчивается так называемый “файловый заголовок” и начинается “Опциональный”.
Следующее поле – MagicNumber. Это тоже константа. Так называемое магическое число. Если честно, я не очень понял, для чего оно служит, в разных источниках это поле преподносится по-разному, но все хором ссылаются на знаменитый дизассемблер HIEW, в котором якобы впервые появилось описание этого поля именно в таком виде. Примем на веру.
Следующие два поля, хоть и не нулевые, но нам малоинтересны. Это: MajorLinkerVersion и MinorLinkerVersion. Это два байта версии компилятора. Угадайте, что я туда поставил?
Следующее важное поле – AddressOfEntryPoint. Важность этого поля в том, что оно указывает на адрес, с которого начинается первая команда, – с нее процессор начнет выполнение. Дело в том, что на этапе компиляции значение этого поля не сразу известно. Ее формула достаточно проста. Сначала указывается адрес первой секции плюс ее размер. К ней плюсуются размеры остальных секций до секции, считаемой секцией кода. Например, в нашей жертве это выглядит так (см. Рис. 7):
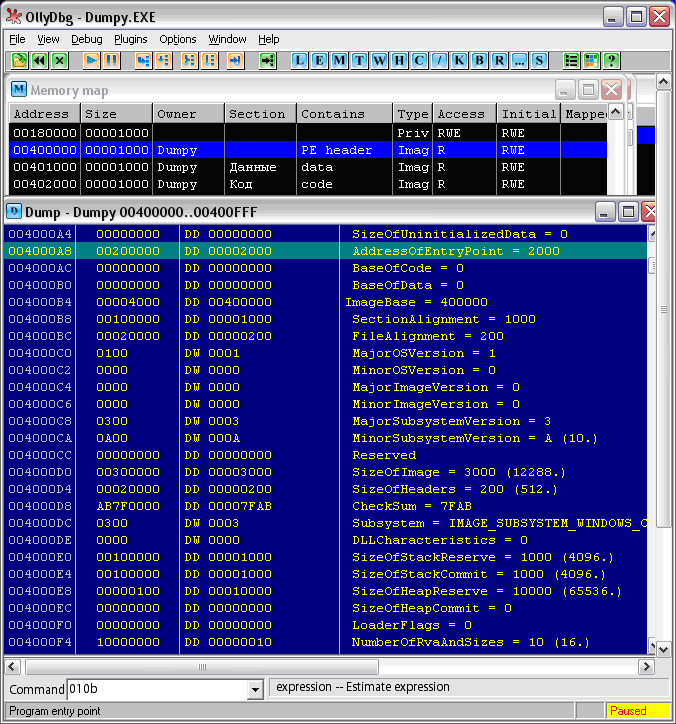
Рис. 7. Расчет точки входа
Здесь секция кода вторая по счету, значит, Адрес точки входа равен размеру секции “Данные” плюс ее начало и равен 2000. К этому еще пририсовывается базовый адрес, в который загрузчик “сажает” файл, но он в вычислении для нашего компилятора не участвует. Поэтому в жертве точка входа имеет значение 2000.
Следующее поле – ImageBase. Это поле я приму как константу, хотя и не оговаривается ее однозначное значение. Это значение указывает адрес, с которого загрузчик поместит файл в память. Оно должно нацело делиться на 64000. В общем, необязательно указывать именно 400000h, можно и другой адрес. Уже не помню, где я слышал, что загрузчик может на свое усмотрение поменять это число, если вдруг в тот участок памяти нельзя будет загружать, но не будем это проверять, а примем на веру как константу =400000h.
Следующая важная константа – SectionAlignment. Это значение говорит о размере секций после загрузки. Принцип прост: каждая секция (имеется в виду ее реализация) дополняется загрузчиком пустыми байтами до числа, указанного в этом поле. Это так называемое выравнивание секций. Тут уж хороший компилятор должен думать самостоятельно, какой размер секций ему взять, чтобы все переменные (или сам код), которые в коде используются, поместились без проблем. Согласно спецификации, это число должно быть степенью двойки в пределах от 200h (512 байт) до 10000h (64 000 байт). В принципе, пока что для простенького компилятора можно принять это значение как константу. Нас вполне устроит среднее значение 1000h (4096 байт – не правда ли, расточительный мусор? На этом весь Windows построен – живет на широкую ногу, память экономить не умеет).
Далее следует поле FileAlignment. Это тоже хитрое поле. Оно содержит значение, сколько байт нужно дописать в конец каждой секции в сам файл, т. е. выравнивание секции, но уже в файле. Это значение тоже должно быть степенью двойки в пределах от 200h (512 байт) до 10000h (64 000 байт). Неплохо бы рассчитывать функцией это поле в зависимости от размеров, данных в секции.
Следующие поля – MajorSubsystemVersion и MinorSubsystemVersion – примем на веру как константы. 3h и Аh соответственно. Это версия операционной системы, под которую рассчитывается данная компиляция****.
* Комментарий автора.
Я не проверял на других ОС: у меня WinXP. В принципе можно не полениться и попробовать пооткрывать “Олей” разные программы, рассчитанные на другие версии Windows.
Я не проверял на других ОС: у меня WinXP. В принципе можно не полениться и попробовать пооткрывать “Олей” разные программы, рассчитанные на другие версии Windows.
Далее из значимых следует SizeOfImage. Это размер всего заголовка, включая размер описания всех секций. Фактически это сумма PE-заголовка плюс его выравнивание, плюс сумма всех секций, учитывая их выравнивание. Ее тоже придется рассчитывать.
Следующее поле – SizeOfHeaders (pазмеp файла минус суммарный pазмеp описания всех секций в файле). В нашем случае это 1536-512 * 2=200h (512 байт). Однако РЕ тоже выравнен! Это поле тоже нужно будет рассчитывать.
Далее следует не менее коварное поле – CheckSum. Это CRC сумма файла. Ужас… Мы еще файл не создали, а нам уже нужно ее посчитать (опять-таки вспоминается Микрософт злым громким словом). Впрочем, и тут можно вывернуться. В Win API предусмотрена функция расчета CRC для области данных в памяти, проще говоря, массива байт – CheckSumMappedFile. Можно ей скормить наш эмбрион файла. Причем веселье в том, что эта операция должна быть самой последней до непосредственной записи в файл. Однако, как показывает практика, Windows глубоко наплевать на это поле, так что мы вполне можем не морочить себе голову этим расчетом (согласитесь, держать в файле поле, которое никому не нужно, да еще и напрягать нас лишним расчетом – это глупо, но, увы, в этом изюминка политики Микрософта. Складывается впечатление, что программисты, писавшие Windows, никак не согласовывали между собой стратегию. Спонтанно писали. Импровизировали).
Следующее поле – Subsystem. Может иметь следующие значения*****:
- IMAGE_SUBSYSTEM_WINDOWS_CUI=3. Это говорит о том, что наш откомпилированный экзэшник является консольной программой.
- IMAGE_SUBSYSTEM_WINDOWS_GUI=4. Это говорит о том, что экзэшник может создавать окна и оперировать сообщениями.
* Комментарий автора.
Для справки, кто хорошо знает Delphi: директивы компилятора {$APPTYPE GUI} и {$APPTYPE CONSOLE} именно эти параметры и выставляет.
Для справки, кто хорошо знает Delphi: директивы компилятора {$APPTYPE GUI} и {$APPTYPE CONSOLE} именно эти параметры и выставляет.
Вот, собственно, и все важные для нас параметры. Остальные можно оставить константно, как показывает “Оля”:
DLLCharacteristics = 0
SizeOfStackReserve = 1000h (4096)
SizeOfStackCommit = 1000h (4096)
SizeOfHeapReserve = 10000h (65536)
NumberOfRvaAndSizes = 10h (16)
SizeOfStackReserve = 1000h (4096)
SizeOfStackCommit = 1000h (4096)
SizeOfHeapReserve = 10000h (65536)
NumberOfRvaAndSizes = 10h (16)
И остаток забить нулями (посмотрите в “Оле” до начала секций, какие там еще параметры). О них можно почитать подробнее по ссылкам, которые я привел.
После идет описание секций. Каждое описание занимает 32 байта. Давайте взглянем на них (Рис. 8):
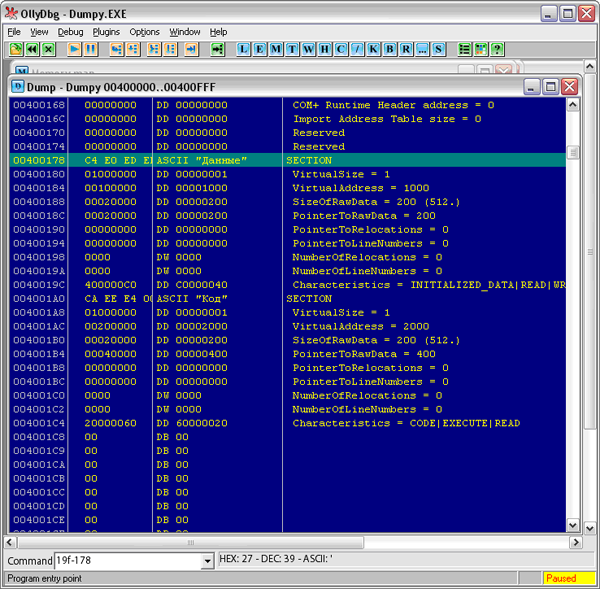
Рис. 8. Описание секций
В начале секции идет ее имя (8 байт), после этого поле – VirtualSize, описывает (я процитирую из уроков Iczeliona) “RVA-секции. PE-загpузчик использует значение в этом поле, когда мэппиpует секцию в память. То есть, если значение в этом поле pавняется 1000h и файл загpужен в 400000h, секция будет загpужена в 401000h”.
Однако “Оля” почему-то показывает для обеих секций одно и то же значение 9. Что это? Я не понял, почему так. Пока оставим это как данное. Вдруг в будущем разберемся.
Далее следует VirtualAddres, который указывает, с какого адреса плюс ImageBase будет начинаться в памяти секция – это важное поле, именно оно станет для нашего компилятора базой для расчета адреса к переменной. Собственно, адрес этот напрямую зависит от размера секции. Следующий параметр PointerToRawData – это смещение на начало секции в скомпилированном файле. Как я понял, этот параметр компиляторы любят подводить под FileAlignment. И последнее – поле Characteristics. Сюда прописывается доступ к секции. В нашем случае для секции кода оно будет равным 60000020=CODE|EXECUTE|READ, а для секции данных C0000040=INITIALIZED_DATA |READ|WRITE.
Вот и все. Закончилось описание заголовка. Далее он выравнивается нулями до 4095 байт (с этим числом связан один прикол). В файле мы его будем дополнять до FileAlignment (в нашем случае до 200h).
Hello world. Hey! Is There Anybody Out There?
Вот мы и прошлись по кишкам нашей жертвы – экзэшника. Напоследок попробуем на скорую руку закрутить простейший компилятор для DOS-системы без PE-заголовка. Для этого подойдут инструменты, которые так почему-то любят преподавать до сих пор.
Я говорю о классическом Паскале. Итак, предположим, злобный преподаватель поставил задачу: написать компилятор программы вывода на экран некой строки, которую мы опишем для компилятора, введя ее ручками (см. листинг 1):
var header,commands,s:string;
e,i:integer;
f:file;
begin
e,i:integer;
f:file;
begin
{Это MZ-заголовок}
header:=#$4D#$5A#$3E#$00#$01#$00#$
00#$00#$02#$00#$00#$01#$FF#$FF#$02#$00#$00;
header:=header+#$10#$00#$00#
$00#$00#$00#$00#$1C#$00#$00#$00#$00#$00#$00#$00;
writeln(
‘give me welcome ![]() ’);readln(s);
’);readln(s);
{Поскольку у нас все в одном сегменте, и код и данные, лежащие непосредственно в конце кода, нужно, чтобы регистр, содержащий базу данных, указывал на код. Предположим, мы будем считать, что и сам код представляет из себя данные. Для этого поместим в стек адрес сегмента кода}
{*******************************************************************************************}
Commands:=#$0E; { push cs}
{и внесем из стека этот адрес в регистр сегмента данных}
Commands:=Commands+#$1F; { pop ds}
Commands:=Commands+#$B4#$09; { mov ah, 9 – Вызовем функцию вывода строки на экран}
{Передадим в регистр DX-адрес на строку. Поскольку пока что строка у нас не определена, передадим туда нули, а позже подкорректируем это место}
Commands:=Commands+#$BA#$
00#$00; { mov dx, }
{Запомним место, которое нужно будет скорректировать. Этим приемом я буду пользоваться, чтобы расставить адреса в коде, который обращается к переменным}
e:=length(commands)-1;
{Выведем на экран строку}
Commands:=Commands+#$CD#$21;
{ int 21h ; DOS – PRINT STRING}
{подождем, пока пользователь не нажмет любую клавишу}
Commands:=Commands+#$B4#$01; { mov ah, 1}
Commands:=Commands+#$CD#$21; { int 21h ; DOS – KEYBOARD INPUT}
{После чего корректно завершим программу средствами DOS}
Commands:=Commands+#$B4#$4C; { mov ah, 4Ch}
Commands:=Commands+#$CD#$21; {int 21h ; DOS – 2+ – QUIT WITH EXIT CODE (EXIT)}
Commands:=Commands+#$C3; {retn}
{*******************************************************************************************}
{Теперь будем править адреса, обращающиеся к переменной. Поскольку само значение переменной у нас после всего кода (и переменная) одно, мы получим длину уже имеющегося кода – это и будет смещение на начало переменной}
i:=length(commands);
{В запомненное место, куда нужно править, запишем в обратном порядке это смещение}
commands[e]:=chr(lo
(i));
commands[e+1]:=chr(hi(i));
{Учтем, что в DOS есть маленький атавизм – строки там должны завершаться символом $. По крайней мере, для этой функции.}
commands:=commands+s+‘$’;
{не забудем дописать в начало заголовок}
commands:=header+commands;
{Теперь скорректируем поле DOS_PartPag. Для DOS-программ оно указывает на общий размер файла. Честно говоря, я не знаю, зачем это было нужно авторам, может быть, когда они изобретали это, еще не было возможности получать размер файла из FAT. Опять-таки запишем в обратном порядке}
i:=length(commands);
commands[3]:=chr(lo(i))
;
commands[4]:=chr(hi(i));
{Ну, и кульминация этого апофигея – запись скомпилированного массива байт в файл. Все заметили, что я воспользовался типом String, – он в паскалевских языках был изначально развит наиудобнейшим образом}
Assign(f,‘File.exe’);rewrite(f);
BlockWrite(f,commands[1],length(commands), e);
Close(f);
end.
Не удивляет, что программа получилась небольшой? Почему-то преподаватели, дающие такое задание, уверены, что студент завалится. Думаю, такие преподаватели сами не смогли бы написать компилятор. А студенты смогут, ибо, как видим, самая большая сложность – это найти нужные машинные коды для решения задачи. А уж скомпилировать их в код, подкорректировать заголовок и расставить адреса переменных – задача второстепенной сложности. В изучении ассемблерных команд поможет любая книга по Ассемблеру. Например, книга Абеля “Ассемблер для IBM PC”. Еще неплохая книга есть у Питера Нортона, где он приводит список функций DOS и BIOS.
Впрочем, можно и банальнее. Наберите в поисковике фразу “команды ассемблера описание”. Первая же ссылка выведет нас на что-нибудь вроде [5] или [6], где описаны команды Ассемблера. Например, если преподаватель задал задачку написать компилятор сложения двух чисел, то наши действия будут следующими:
- Выясняем, какая команда складывает числа. Для этого заглянем в книгу того же Абеля, где дается такой пример:
сложение содержимого
ADD AX,25 ;Прибавить 25
ADD AX,25H ;Прибавить 37 - Значит, нам нужна команда ADD. Теперь определимся: нам же нужно сложить две переменные, а это ячейки памяти; эта команда не умеет складывать сразу из переменной в переменную, для нее нужно сначала слагаемое поместить в регистр (AX для этого лучше подходит), а уж потом суммировать в него. Для помещения из памяти в регистр (согласно тому же Абелю) нужна команда
mov [адрес], ax
- Таким образом, инструкции будут выглядеть так:
mov [Адрес первой переменной], ax
add [Адрес второй переменной], ax - Теперь нужно определиться с кодами этих команд. В комплекте с MASM идет хелп, где описаны команды и их опкоды (машинные коды, операционные коды). Вот, например, как выглядит опкод команды MOV из переменной:
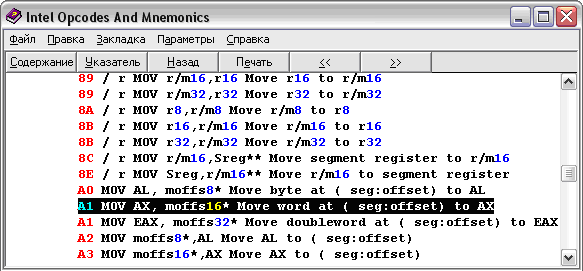
Рис. 9. Опкоды MOV
Видим (см. Рис. 9), что его опкод A1 (тут тоже любят 16-тиричность). Таким образом, выяснив все коды, можно написать компилятор что-то вроде этого (см. листинг 2):
Commands:= Commands+#$A1#$00#$00; { mov [Из памяти] в AX}
aPos:= Length(Commands)-1;{Запомним позицию для корректировки переменной a}
Commands:= Commands+#$03#$06#$00#$00;
{ $03 – Это опкод команды ADD $06 – Это номер регистра AX}
bPos:= Length(Commands)-1;{Запомним позицию для корректировки переменной b}
Commands:= Commands+#$A3#$00#$00; { mov из AX в переменку b}
b2Pos:= Length(Commands)-1;
{Запомним позицию для корректировки для переменной b}А далее, в конце, скорректируем эти позиции (см. листинг 3):
commands:= commands+#$01#$00; {Это переменка a, ее значение}
i:= length(commands);
commands[aPos]:= chr(lo(i)); {Не забудем, что адреса в перевернутом виде}
commands[
aPos+1]:= chr(hi(i)); {Поэтому сначала запишем младший байт}
commands:= commands+#$02#$00; {Это переменка b, ее значение}
i:= length(commands);
commands[bPos]:= chr
(lo(i)); {Поскольку переменка b фигурирует в коде}
commands[bPos+1]:= chr(hi(i)); {дважды придется корректировать ее}
commands[b2Pos]:= chr
span style=”color: #66cc66;”>(lo(i));
commands[b2Pos+1]:= chr(hi(i));Запустим компилятор, он скомпилирует экзэшник, который посмотрим в “Иде” (см. Рис. 10):
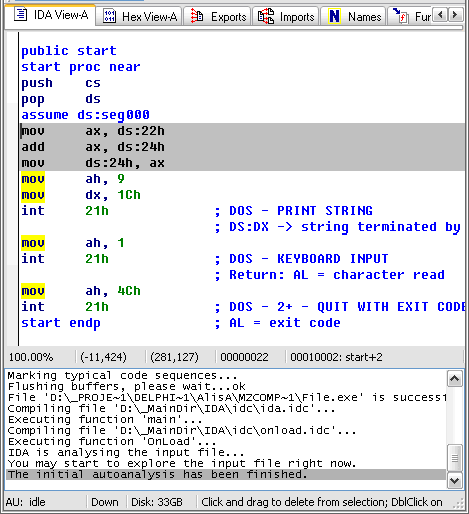
Рис. 10. Реверсинг нашего кода
Все верно, в регистр пошло значение одной переменной, сложилось со второй и во вторую же записалось. Это эквивалентно паскалевскому b:=b+a;
* Комментарий автора.
Обратите внимание: значения переменных мы заранее проинициализировали. При желании можно сделать, чтобы компилятор спросил их инициальное значение, и подставить в нужное место:
Обратите внимание: значения переменных мы заранее проинициализировали. При желании можно сделать, чтобы компилятор спросил их инициальное значение, и подставить в нужное место:
commands:=commands+#$01#$00; {Вот сюда вместо этих циферок}.
Post Scriptum
Ну как, студенты, воспряли духом? Теперь понятен смысл, куда двигаться в случае столкновения с такими задачами? Это вряд ли потянет на курсовую, но вполне подойдет для простенькой контрольной. А вот следующая задача – написать транслятор – уже действительно тянет даже на хороший диплом, так что пока переварим все то, что выше, а в следующий раз попробуем приготовить основное ядро компилятора, дабы потом уже делать упор на сам код программы.
The Чтиво
- Ресурс Википедии по языку LISP http://ru.wikipedia.org/wiki/Lisp
- Ресурс Википедии по формату PE http://ru.wikipedia.org/wiki/PE
- Ресурс Википедии по формату MZ http://ru.wikipedia.org/wiki/MZ_(формат)
- Micheal J. O’Leary (Microsoft). The portable executable format http://www.nikse.dk/petxt.html
- Описание простейших команд Ассемблера http://students.uni-vologda.ac.ru/pages/it10/2.php
- Питер Абель. Ассемблер и программирование для IBM PC. – British Columbia Institute of Technology
Статья из шестого выпуска журнала “ПРОграммист”.
Обсудить на форуме — Компилятор домашнего приготовления. Часть 1
19th
Июл
Универсальный совет для дизассемблирования
Это очень обширная тема, и, естесственно, не бывает универсальной методики, а бывают килограммы книг по дизассемблированию (копать в сторону Криса Касперски). Но вот есть что-то общее для этой темы:
Здравствуйте уважаемые формучане, есть проблемма с получением исходников из ехе приложения, упакован Armadilio, помогите советом, или прийдется позновать все тонкости дизассемблирования ((((….
1) Открой прогу в PEID(можно скачать с www.cracklab.ru) и определи версию упаковщика Armadillo.
2) Распакуй(распаковщик для Armadillo на этом же сайте) свою прогу и еще раз
открой в PEID(или можно в EXEINFO) чтобы узнать на чем же писали и версию компилятора.
3) Если нужен диззассемблированный код открой в OllyDebuger v 1.10(не 2.0) или
IDA advanced pro и анализируй код до посинения.
4) Если нужен именно исходник то после определения на чем писалось и версии
компилятора делай так:
Если покажет Delphi то декомпилируй в DeDe
Если С++ то декомпилер от HexRays тебе в руки(кстати вместе с IDA как плугин
прикрепляют).
Если честно современными декомпиляторами можно получить многое о коде но не
все(Даже и не думай об обратной компиляции исходника полученного таким способом). Поэтому шоб получить читабельный компилябельный код надо хроршо
погимориться над этим.
Кстати еще можно попробовать SourceRescuer для декомпиляции С++ Builder
Облако меток
css реестр ассемблер timer SaveToFile ShellExecute программы массив советы word MySQL SQL ListView pos random компоненты дата LoadFromFile form база данных сеть html php RichEdit indy строки Win Api tstringlist Image мысли макросы Edit ListBox office C/C++ memo графика StringGrid canvas поиск файл Pascal форма Файлы интернет excel Microsoft Office Excel winapi журнал ПРОграммист DelphiКупить рекламу на сайте за 1000 руб
пишите сюда - alarforum@yandex.ru
Да и по любым другим вопросам пишите на почту

пеллетные котлы

Пеллетный котел Emtas

Наши форумы по программированию:
- Форум Web программирование (веб)
- Delphi форумы
- Форумы C (Си)
- Форум .NET Frameworks (точка нет фреймворки)
- Форум Java (джава)
- Форум низкоуровневое программирование
- Форум VBA (вба)
- Форум OpenGL
- Форум DirectX
- Форум CAD проектирование
- Форум по операционным системам
- Форум Software (Софт)
- Форум Hardware (Компьютерное железо)
